随着互联网技术的飞速发展,微博作为当今社会重要的信息传播平台,其数据量呈现爆炸式增长。这些数据不仅包含公共话题和用户互动信息,还可能涉及敏感内容和潜在的安全威胁。因此,设计并实现一个基于爬虫技术的网络空间微博信息管理系统具有重要的实践意义。该系统结合网络与信息安全软件开发理念,能够高效采集、存储、分析并管理微博平台上的公开信息,同时保障数据处理的合规性与安全性。
系统设计采用分布式爬虫架构,以提高数据采集效率并避免对目标平台造成过度访问压力。爬虫模块基于Python的Scrapy框架开发,支持多线程与代理IP轮换技术,确保在遵守平台Robots协议的前提下,稳定抓取微博用户的公开帖子、评论及转发数据。系统通过模拟用户登录与动态页面渲染技术(如Selenium),应对微博平台的反爬虫机制,同时设置合理的请求间隔与去重策略,以维护数据采集的合法性与持续性。
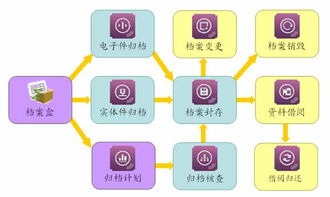
在数据管理方面,系统采用MySQL数据库存储结构化数据(如用户信息、博文内容),并结合Elasticsearch实现全文检索与快速查询功能。对于非结构化数据(如图片、视频),系统使用分布式文件存储方案(如HDFS),以优化存储效率与可扩展性。数据处理模块包括数据清洗、去噪与情感分析功能,通过自然语言处理技术识别潜在敏感内容,并生成可视化报表,辅助管理员进行决策。
信息安全是系统的核心考量。系统集成身份认证与访问控制机制,确保只有授权用户可操作数据。在数据传输过程中,采用HTTPS协议加密,防止中间人攻击。系统部署日志审计与异常检测模块,实时监控爬虫行为与数据流向,及时发现并响应安全事件。为符合数据隐私法规,系统内置数据脱敏功能,对个人敏感信息进行匿名化处理,避免侵犯用户隐私。
在实现过程中,系统采用模块化开发模式,前端使用Vue.js构建用户界面,后端基于Spring Boot框架提供RESTful API,实现前后端分离。测试阶段通过单元测试、集成测试与压力测试,验证系统的稳定性与性能。系统不仅能够高效管理微博信息,还为网络空间治理与舆情分析提供了可靠工具。
该网络空间微博信息管理系统通过爬虫技术与信息安全开发的结合,实现了对微博数据的全面管理与智能分析。它不仅适用于学术研究与商业应用,还为网络空间安全治理提供了技术支持,具有广泛的应用前景。